SUCHO
SUCHO workflow
How we’ve organized things (last updated March 15th).
Send SUCHO a link (or several!)
Anyone can send us links, with or without volunteering.
- Send us website links through our webform to let us know about more Ukrainian heritage sites.
- A couple times a day, we’ll add your links to our working collection.
- Visit our public list of rescued sites to see what we’ve completed. (If your site doesn’t appear here, it’s still in progress within our team.)
Joining the team
Want to get more hands-on? Great!
- Fill out our our volunteer form
- If you don’t have Slack already, make a Slack account. You can either download the Slack app or use the web interface (after you’ve logged in) to work with us.
- Admins go through the form a couple times a day and add people with the skills we currently need to our SUCHO Slack space where all the work is coordinated.
- People with other skills remain on the standby list until we have tasks for them.
- Once you’ve joined our Slack channel, check out our Orientation page.
Things to do
Low tech helping
We have several teams working on projects that mostly need a web browser and enthusiasm (you don’t even need to read Cyrillic for most of these).
- Link collection: Teammates will have edit access to our working spreadsheet. You should add newly discovered links to the Browsertrix tab first, because it will automatically check for duplicates found elsewhere. If it’s not a duplicate (i.e. doesn’t turn magenta), please also add it to the Internet Archive tab, because there are two capture processes running at the same time for different purposes.
- Internet Archive: Newly submitted links get added to the InternetArchive tab of our working sheet (along with Browsertrix, described below). Volunteers make sure that the sites are thoroughly captured by the Wayback Machine, including sub-pages.
- Manual Webrecorder: While many of our sites can be captured by the automated system called Browsertrix, some of them (and some special features such as virtual tours within a site) need a human being to navigate the site while recording it. Join the Manual Webrecorder team if you like browsing museum and library websites! Visit the ArchiveWeb.page tutorial for more process specifics.
- Metadata (great for cataloging librarians): Some volunteers have uploaded files (e.g. PDFs, images, etc.) from Ukrainian repositories to the Internet Archive. The Metadata group fills out a separate metadata spreadsheet with metadata about those items based on information in our working spreadsheet. This information is periodically uploaded to the Intenet Archive. Visit the Metadata tutorial for more process specifics.
High tech helping
- Browsertrix: Newly submitted links go to the Browsertrix tab of our working spreadsheet (along with InternetArchive). Browsertrix is an automated web crawler using the open-source Webrecorder software, and volunteers run it on their laptops, on servers they manage, or even on Raspberry Pi devices! You need to be a little bit familiar with the command line to run Browsertrix, but we have a step-by-step tutorial for how to get it set up. Visit the Browsertrix tutorial for more process specifics.
- Scraping: Some sites, like library catalogs and repositories, don’t have URLs that an automated web crawler can easily follow, so the scraping group writes custom code to capture the contents of those sites. Intermediate-to-advanced coding skills (preferably Python) are needed to help with this group. There are also special sub-groups of scraping with channels on Slack, like #repository-talk and #irbis. If you’re not sure how to approach the site, check in the channel for the type of site you’re working with, or (if you’re not sure) in Browsertrix. (Most of our programmers hang out there.)
- Dataviz: This group in the #inventory-dataviz channel is working on visualizing what SUCHO has captured so far. Intermediate-to-advanced coding skills are needed.
Can you read Ukrainian?
In addition to the Link Collection and Metadata volunteer groups above, there are a couple of teams where reading Ukrainian is a vital prerequisite:
- Quality control: After we’ve backed up a site using tools such as Browsertrix or ArchiveWeb.page, we need people with Ukrainian language skills to browse around our copies of the site and make sure that our backups are working as intended.
- Translation: We’re doing direct outreach to some sites to see if we can contact their administrators, and help with translation of correspondence and news materials is always helpful.
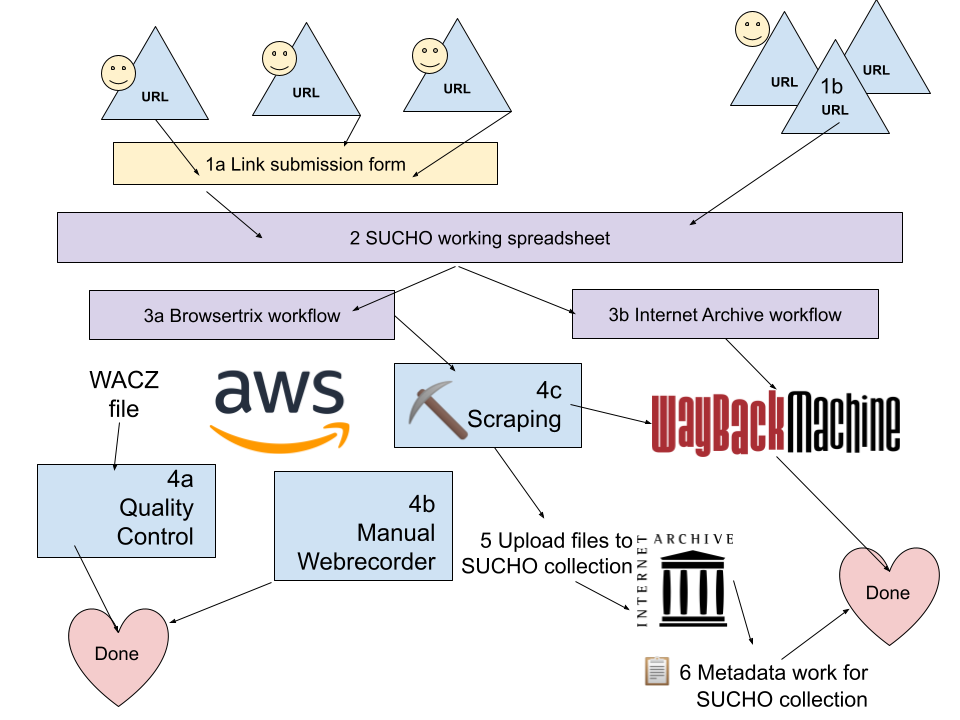
How it all fits together
The diagram below this explanation draws out how the pieces of this project work together.
Anyone can submit a link to SUCHO via our web form (1a). If you already have a large list of links to submit, reach out to info@sucho.org and we can accept a spreadsheet (1b).
Links go into the SUCHO working spreadsheet (2), and from there are sent to both the Browsertrix workflow (3a) and the Internet Archive workflow (3b).
The Internet Archive workflow (3b) involves making sure that the sites – including sub- and sub-sub-pages – are well captured by the Wayback Machine. Sometimes we need to submit new URLs to the Wayback Machine to capture the whole site as part of this process.
The Browsertrix workflow (3a) involves volunteers running Browsertrix (automated Webrecorder software) to generate a web archive file (WACZ) that is stored on the SUCHO server hosted by Amazon Web Services. WACZ files that appear to be created successfully go to quality control (4a). If there are problems with the WACZ file, it goes back to the Browsertrix workflow (3a), otherwise it’s considered done.
Sometimes the Browsertrix workflow isn’t (fully) successful, because there are some materials that aren’t captured well by the automated crawler. Pages that require user interaction (e.g. virtual tours, complex Javascript) go to a Manual Webrecorder workflow (4b) for completion. Pages that don’t have an easy set of navigable links (e.g. DSpace sites, library catalogs) go to a custom Scraping workflow (4c).
The custom scraping workflow (4c) varies depending on the site; it may produce a set of links that go to the Wayback Machine (3b), or it may produce a set of files (images, PDFs, etc.) that get uploaded to the SUCHO collection at the Internet Archive (5). Volunteers then enhance the metadata for uploaded files (6).