SUCHO
Overview
Browsertrix enables you to run automated web crawls using SUCHO’s cloud servers, without having to install anything on your computer.
The command-line version of Browsertrix gives you more control over things like path exclusions (e.g. to avoid crawling through lots of empty past-event calendar pages) and timeout rules (which help with very slow sites), so if you’re comfortable working with the command line, we encourage you to use that route. Otherwise, read on for how to run automated crawls with Browsertrix!
To start using Browsertrix, you can go to the SUCHO Browsertrix site and sign-up, or log in with the credentials you used to sign up before. (Please contact us if you need the URL.)
Sign up for an account
If you don’t have an account yet, click Sign Up in the top right. You will then see a sign-up box where you can enter your e-mail, password and name. The name you use will show up in the UI, and will be part of the filename of the archives you create.
Once you click Sign Up, you will be automatically logged in and ready to start archiving!
You will see an archive called Your-Name’s Archive.
A confirmation e-mail will also be sent to you. For now, it is not required to use the service.
Log in
If you’ve already signed-up, you can log in with existing credentials. You can also request a password reset if needed.
Archives
Once you’ve logged in, you’ll see Your-Name’s Archive. Click on this link and you’ll be taken to your personal archive. (If others have invited you to join their archive, its possible other archives will appear in the list as well. For SUCHO, all data is going in the same place, so we’re giving everyone their own archive to make it easier to organize).
This will take you to a page with tabs at the top for “Crawls” (where you can see currently active crawls) and “Crawl Templates”. Click on “Crawl Templates”, which is where you can configure the setup for capturing a website.
Selecting a website to crawl
Once you receive access to the SUCHO spreadsheet, before you click on a link and open it in your browser, please read our security guidelines. To be on the safe side, you may want to backup your personal files stored on your computer.
Go to the Browsertrix tab of the SUCHO working spreadsheet and pick a site to work on that no one has claimed yet. To claim the site, on that row of the spreadsheet, add your name to the ‘Claimed By’ column, and update the ‘Status’ column to ‘in progress.’
To avoid downloading malware, run a security check by copying the link into this security checker. A “Medium” risk shouldn’t pose a threat to you if the security check verifies that no “malware” or “injected spam” is detectable on the site.
Prioritize sites with links ending in .ua. Check where they are hosted and focus on sites in Ukraine and environs using Hosting Checker or IP-Lookup. Just because a site shows it is hosted in San Francisco on Cloudflare doesn’t mean it’s not hosted Ukraine. Besides verifying its server location, you might want to double check the site is still live by loading the ‘Collection Url’ in your browser.
Configuring crawl templates
Click the big button that reads Create New Crawl Template. This will take you to a form you’ll need to fill out.
- Basic settings: The name should be the base URL of the website you’re working on, with periods replaced by hyphens. So if you’re working on http://dcvisu.sikorsky.kiev.ua, the name should be
dcvisu-sikorsky-kiev-ua. This name will be used for the web archive file that gets created at the end, so using this convention to name your crawl template will make it easier for us to match it up with site metadata for QC. - Crawl settings
- Crawl scale: This setting determines how many browsers will be used to simultaneously capture different pages on the site. Start with the default “Standard” (which launches 8 simultaneous browsers), but if the site is responding quickly and appears to have many pages, you can change this setting even as the crawl is running. “Big” launches 16 simultaneous browsers, and “Bigger” launches 24.
- Seed URLs: This should be the base URL of the site you want to capture (e.g.
http://dcvisu.sikorsky.kiev.ua.) If you see a URL in the sheet that has text after the base domain (e.g.http://dcvisu.sikorsky.kiev.ua/page/something/else.html), just use the base domain and leave off everything after the first slash. - Scope type: We usually recommend “Domain” for this setting, which will also capture any subdomains (e.g. http://thing1.site.ua and http://thing2.site.ua along with http://site.ua)
- Do not check the box for external links – Browsertrix will crawl the pages of the site just fine without it
- Page limit should stay with the default “unlimited”
- Crawl schedule: use the default settings (not recurring, run immediately on save)
Once you’ve filled out this form, hit the big blue Save Crawl Template button at the bottom.
Advanced Options / JSON Editor
You can also click the Use JSON Editor toggle, which will show a JSON editor. Here you can enter a custom Browsertrix Crawler config file using JSON syntax.
We don’t recommend using this to start, but if you have advanced options, or were previously using Browsertrix Crawler via command-line, you can enter your config here.
Monitoring the crawl
Crawls take 1-2 minutes to start, and you’ll be able to see their status on the Archives page. You can click on a crawl to look at the details. On the left-hand tabs, you can click “Watch Crawl” to watch the web browser(s) and what they’re currently capturing.
Currently, the crawl is configured to run 8 browsers, and can be scaled up to 16 or 24 browsers. We suggest starting with 8 and only scaling up if it seems that the site can handle this load.
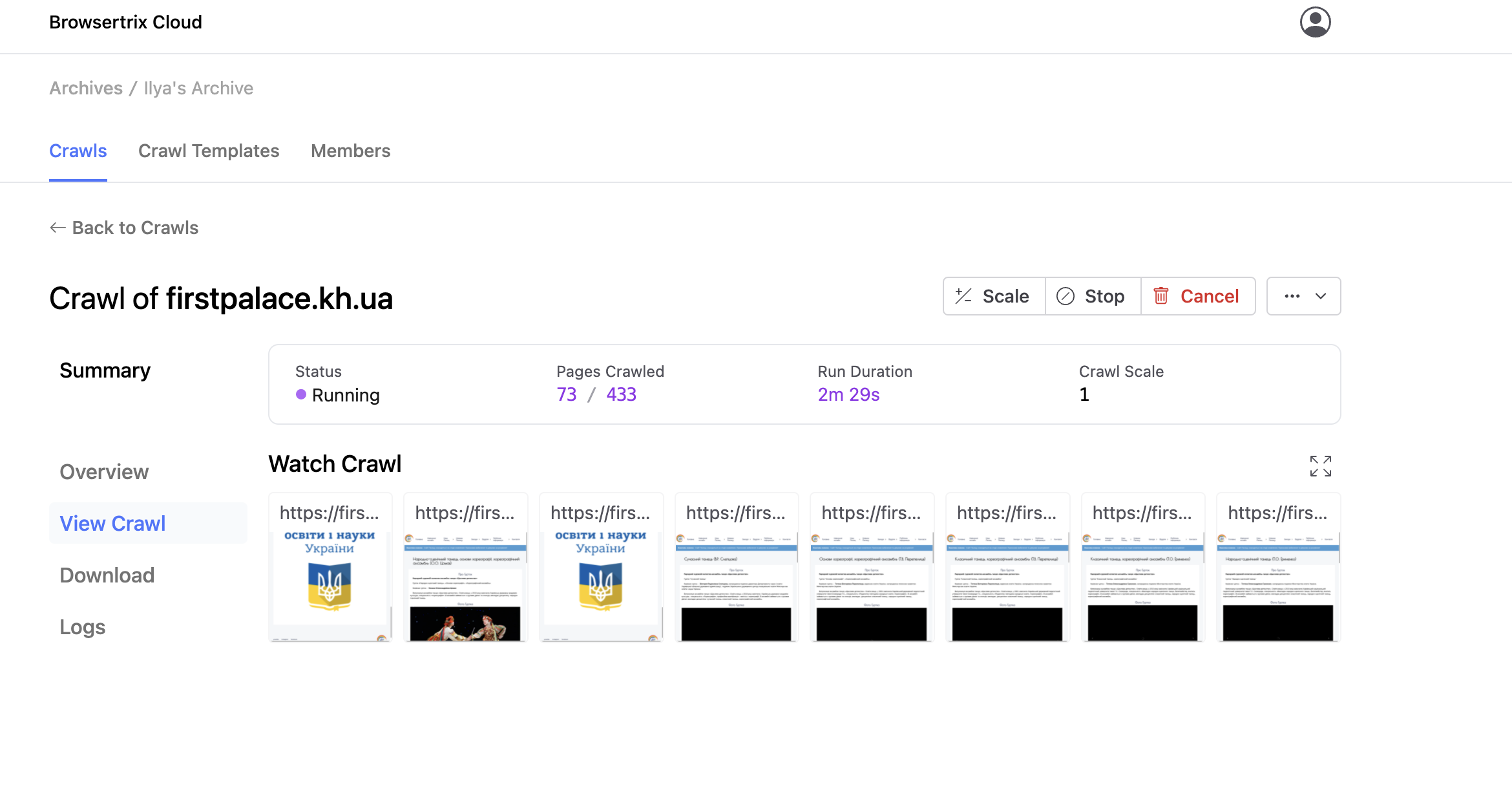
In the crawl view, you can also click on each browser to zoom in.
Viewing the Replay
Once the crawl is done, the ‘Replay’ link will show you the replay using an embedded version of ReplayWeb.page.
Downloading the WACZ
From the download tab, you can download the WACZ file if you would like to have a copy or test it locally. Note that you do not need to upload it, as it is automatically added to the SUCHO cloud storage.
Completing the crawl job
Verify the website was captured by using the ‘Replay’ link on the crawl page to check the output. Focus on verifying that the main subcomponents of the site were saved, especially pages listed in the navbar. Many links on the site may be external to the domain you preserved, so don’t worry if those are broken.
Make sure to add info the Notes field about any errors you encountered and any concerns you have about the quality of the archive file. The Quality Control team can verify your lingering questions.
At this point, your crawl is complete! Thank you for your work.
Please mark in the spreadsheet the row’s status as “Done” and continue on to the next item.
Adding more crawl templates
We recommend that you have no more than 10 crawl templates running at a given time, and that you keep an eye on them to make sure they’re successfully running. You can add more crawl templates as crawls complete.
WACZ files (the web archives produced through this workflow) are already automatically stored on SUCHO’s servers, so you don’t need to upload anything at the end.
Troubleshooting crawl templates
If a crawl template completes with only 1 page, something went wrong in the crawl template configuration. A common error is using http instead of https, or vice-versa. You can try it again, or otherwise, mark it as incomplete in the SUCHO working spreadsheet and someone else will try it.
Limitations
It is not currently possible to stop a crawl, edit the config (for example, to add exclusions) and continue. You can stop or cancel a crawl, but not start it again with different rules.